基于play framework的APP托管平台的设计与实现(北京邮电大学 硕士论文 2018)
- bsdiff/bspatch+Linux rsync
基于文件分块的大文件更新策略
解决的问题
- 客户端使用bspatch进行解压时,内存消耗过大
- 客户端本地的旧文件可能不完整或者受损,而bspatch需要完整的源文件
- 频繁更新场景下,服务器需要多次进行bsdiff,消耗时间长;并且需要管理多个版本的差分包
基本思路
- 服务端
- 对新文件进行滚动校验,生成校验表
- 两个校验表
- 弱校验:速度快但冲突概率高,采用Adler-32
- 强校验:速度慢但冲突概率小,采用MD5
- 两个校验表
- 对新文件进行滚动校验,生成校验表
- 客户端
- 下载服务端的新文件校验表
- 对本地文件进行滚动校验(先弱校验,如命中再强校验)
- 如果两次校验的结果在新文件校验表中均命中,则将该块标记为匹配部分,指针后移一个块
- 如果未命中,则将该字节标记为不匹配,指针后移一个字节
- 从服务器下载未匹配的部分
- 将下载到的未匹配部分与本地的匹配部分进行合成
A Software Update Scheme by Airwaves for Automotive Equipment(2013 International Conference on Informatics, Electronics and Vision (ICIEV))
解决的问题
- 将bsdiff/bspatch应用到汽车上会面临着几个问题:
- 内存限制
- 不稳定的电源供应
- 不稳定的无线电波传输
方法
原地更新
- 原地更新的挑战:写冲突,即前面的编辑操作修改了后面的编辑操作所要引用的旧二进制的空间
- bsdiff场景:preceding Copy & Modify and New edit operations
- 性能
- 原空间复杂度:u+v+w+O(1)
- 新空间复杂度:max(u,v)+w+O(1)
原地更新相关文章
[11] R. C. Burms and D. D. E. Long, “In-Place Reconstruction of Delta
Compressed File,” ACM Symp. on Principles of Distributed Computing,
pp.267–275, Jul. 1998.
[12] D. Shapira and J. A. Storer, “In Place Differential File Compression,”
The Computer Journal Advance Access, Vol.48, pp.667–691, Aug. 2005.
[13] Y.-C. Cho and J. W. Jeon, “In-Place Reconstructible Delta Compression Using Alleviated Greedy Matching Algorithm,” Proc. Int. Conf. on
Industrial Informatics (INDIN2008), pp.1596–1601, Jul. 2008.
In-Place Reconstruction of Delta Compressed Files (PODC ‘98 CCF-B)
解决的问题
当差量指令指示计算机从一个文件区域复制数据时,新的文件数据可能已经被写入

基本思路
基于图论
对差分文件进行后处理
- 对尝试读取已写入区域的指令进行检测
- 对这些指令进行排序,以减少冲突的出现
- 对于剩余的冲突,删除这些指令,改为显式添加(会增大差分文件的大小)
修改差分文件为可就地重建的,花费的时间比生成差分时间还要长
- (Conclusion又说时间更短,矛盾)
过程:一个原地重建算法
- 定义copy指令为三元组*<f,t,l>*
- f:源串中的地址
- t:目标串中的地址
- l:复制长度
冲突检测
- 对于copy指令*<fi,ti,li>和<fj,tj,lj>*,i<j,存在一个WR冲突,当:[ti,ti+li-1]∩[fj,fj+lj-1]≠{}
- 与add指令相关的潜在WR冲突可以通过把add放在所有copy的末尾来避免
- 这种冲突出现于add先写,copy后读
- copy指令的自冲突问题:读与写的区间重叠
- 解决方法
- 当f>=t时,从左到右逐字节复制
- 当f<t时,从右到左逐字节复制
- 解决方法
- 三个方法:
- 将所有的add放到差分文件的末尾
- 将copy指令排序,以减少WR冲突
- 对于剩余的WR冲突,将对应的copy指令转为add指令,并且放到差分文件的末尾
生成无冲突的排列
将copy指令按照t进行排序
将所有的copy指令用顶点表示
如果顶点u的读区间与顶点v的写区间重合,则创建一条边u->v
执行增强版的拓扑排序
- 如果检测到环,移除一个顶点(转为add)以消除环
- 移除最佳顶点以减少压缩损失是一个NP难问题
- 两种策略:
- 常数时间策略:选择最容易移除的顶点
- 局部最小策略:遍历环,选择删除开销最小的顶点,即copy的长度最小的指令
- 如果检测到环,移除一个顶点(转为add)以消除环
将拓扑排序后的copy指令写入输出文件,再将add指令写入输出文件
实验
数据集:GNU工具、BSD操作系统
压缩损失:
- 局部最小策略:2.4%
- 常数时间策略:5.9%
In Place Differential File Compression(DCC 03 CCF-B and The Computer Journal 05)
基本思路
- 提出了IPSW算法
- 将窗口初始化为S,将其最大尺寸限制为max(|S|,|T|)来对T进行解压
- 速度快,压缩效果好
- 当S和T有合理程度的对齐时(即S和T的大量匹配以大致相同的相对顺序出现),IPSW最有效
- 这种对齐在很多应用中是典型现象
- 当S和T不对齐时,对S进行预处理
- 压缩文件之前有一个位标识该文件是否经过预处理
- 编码器用IPSW对T进行压缩,与对S的压缩进行对比
- 如果差别很大,则设置初始位,进行对齐预处理,在IPSW编码前增加一个移动列表
- 解码器先原地执行这些动作,再执行正常的IPSW解码
- 本文直接生成可原地构建的差分文件,而不是对差分文件进行可原地构建处理
- 本文同时实现了就地压缩和就地解压
原地移动子串(压缩前置知识)
定义源串S,目标串T
差分文件包含一些移动指令(对应S和T匹配的块)和一些压缩数据(对应不匹配的部分)
解压流程如下:
- 对于收到的每条移动指令,对T的子串就地执行移动
- 对于压缩数据,进行解压,然后填补移动后的空隙
- 步骤2可以应用任何无损压缩方法
定义s为S中一个即将被移动的子串,l为s的长度,x为原位置,y为目标位置
- 本文定义的”移动“并不是简单覆盖,例如:当s往右移动1个字符时,原本在s右边的那个字符要变到s左边,而不是被覆盖
就地移动子串的高效方法:
- 过程
- 不失一般性,令x=0,假设向右移动
- 对0到y-1的字符,进行排列:i → (i + d) MOD y
- 执行排列的方法
- 标准方法:O(y)时间、y比特的标记位空间
- 一个理论方法:O(1)空间,但在实际应用中节省y比特的标记位空间并不重要
- 过程
当S和T对齐的情况下,移动只需要简单的字符串拷贝:
两次扫描文件,首先从左到右复制移动到左边的块,再从右到左复制移动到右边的块
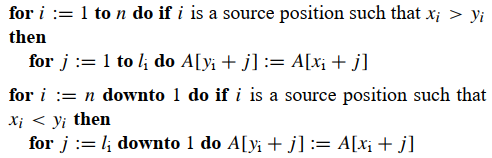
实际执行过程可以设置多个阈值,分步贪心查找匹配的窗口
原地滑动窗口(压缩、解压缩过程)
- 问题:给定一个长度为m的串S,一个长度为n的串T,以及字符插入、块删除、块移动和块复制的操作集,计算将S转化为T所需的最小操作数
- 即压缩过程如何生成最小的差分文件
- 是一个NP-完全问题
- 可以通过一个简单的从左到右的贪婪复制算法(全窗算法)近似到一个恒定的常数内
- 全窗编码算法:略
- ISPW算法:
- 构建字符串ST
- 在一个滑动窗口max(m,n)内,从左到右贪心地寻找与接下来的子串匹配的子串(使用上一节最后一部分叙述的分步贪心查找方法)
- 使用ISPW算法进行压缩后,由于限制了匹配子串只能在大小为max(m,n)的滑动窗口内进行查找,因此解压时所占用的内存空间也是max(m,n)
移动预处理算法(MP)
先不看
实验
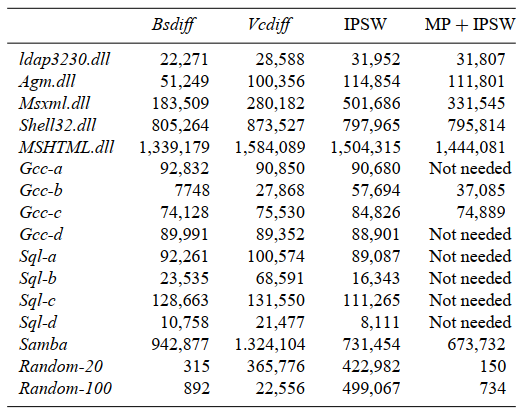
- IPSW的压缩率与bsdiff接近
- 针对部分文件(如sql和部分的gcc),即使不采取MP,IPSW的压缩率也能优于bsdiff
- 即使采取了MP,IPSW针对dll文件的压缩率表现也比较差,少部分较好
- 我的结论:用IPSW实现原地解压后导致的压缩率损失与具体的文件格式有关系
In-Place Reconstructible Delta Compression using Alleviated Greedy Matching Algorithm(INDIN 08)
解决的问题
现有方案的问题
- Burns and Long的方案将COPY指令替换为ADD指令,增加了差分文件的大小
- Shapira的方案使用了原地滑动窗口算法,然而解码时移动字符串几乎需要O(m)时间,使得解码器变得更加复杂,不适合于嵌入式系统;并且预处理步骤还会增大差分文件的大小
本文解决了这两个问题,适合于小内存和低计算能力的嵌入式系统
前置知识
找匹配串的方法
- 最优的找匹配串方法:后缀树。但需要线性空间,不适用于大文件
- 另一种方法:哈希方法。如Karp-Rabin哈希,可以递推计算
贪心方法
创建一个哈希表,保存指纹对应的所有下标(以链表形式)
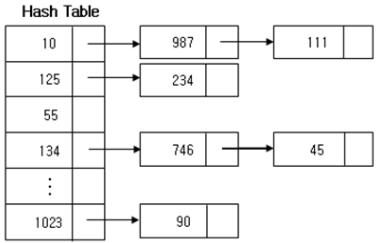
算法对fnew当前位置的串进行哈希,在哈希表中找到最长匹配的串
- 如果匹配失败,则fnew下标加1
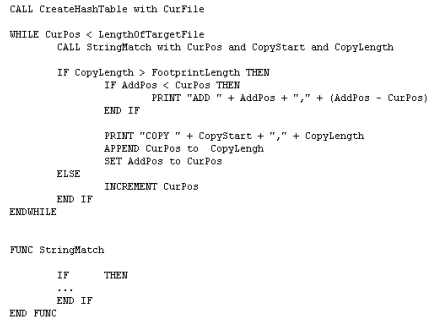
伪代码如下,注意APPEND和SET的被操作数是前面的变量:
方法:缓解的贪婪匹配算法
选取避免WR冲突的字符串匹配,而不是最长匹配
现有的确定最佳匹配串的贪心算法有如下两个标准:
- 匹配串长度
- 距离当前位置的offset
本文增加了一个标准:
- 是否有WR冲突(这个标准是最重要的)
伪代码:
- 当一个匹配串在旧文件当中,且下标在当前编码位置之前,则代表会发生WR冲突。该匹配节点将被移除
- 遍历完链表后,在所有不会发生WR冲突的节点当中找最佳匹配串

实验
- 本文在zdelta上应用了本方法,与原始zdelta和Burn的方法进行对比
- 本文方法生成的差分文件大小略小于Burn的方法
- 由于差分文件更小,本文的解压内存占用也略小于Burn的方法
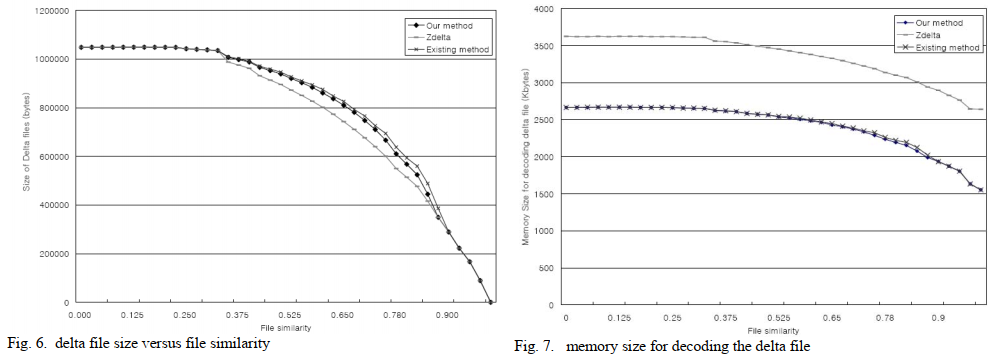
Dfinder—An efficient differencing algorithm for incremental programming of constrained IoT devices(IOT 22)
贡献
- 本文提出了Dfinder
- 字节级
- 使用增强的后缀数组,可以有效产生小的差分文件
- 可以正向和反向检测共同片段,还可以使用新固件中已经被重建的部分
- O(nlogn)时间,O(n)空间
- 提出Dfinder的一个模式,允许就地重建
物联网空中编程前置知识
物联网领域使用的操作系统,如ContikiOS[18],是模块化系统,支持动态链接[19]和加载;因此,就OTAP而言,它们只需要接收新固件映像的修改部分,因为在接收时,动态链接器会重新链接映像并再次加载它。可能会出现大量的开销,因为除了修改的部分,新的符号和重定位表也需要传输。Elon[20]通过引入可替换部件的概念来解决这个问题,这些部件包括。(i) 可替换的代码,(ii) 可替换的数据,以及(iii) 系统跳转表。然而,一个缺点是,这些(组件)存储在节点的RAM中,随后在系统重置的情况下需要重新传输。
相关算法:
- Xdelta
- BSDiff
- RMTD
- DASA
- R3
- JojoDiff
- DG
增强的后缀数组
- 增强的后缀数组=后缀数组SA+辅助数组(LCP数组、𝛷-数组等)
- Dfinder使用divsufsort
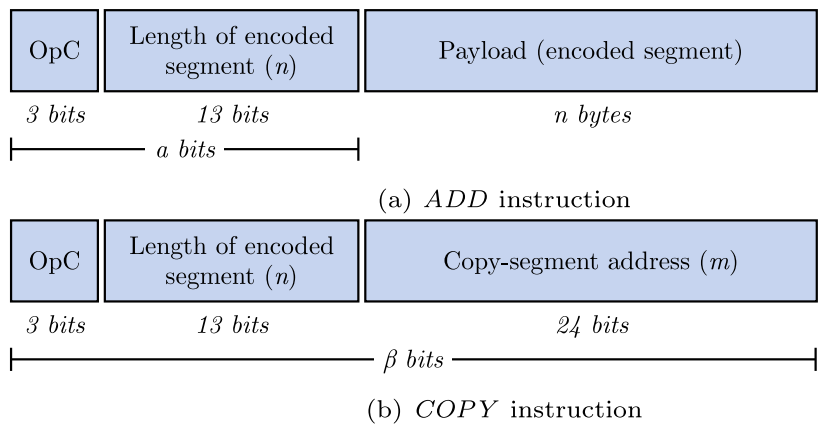
Dfinder
指令
COPY(Copy_typeX|X=1,2,3,4),取决于BMD所检测的匹配片段的类型
ADD,连续的ADD指令可以合并
过程
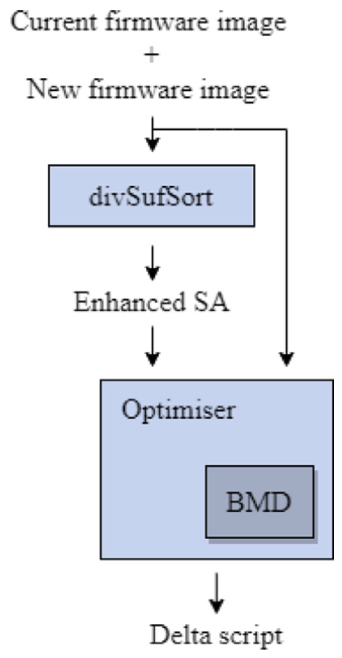
块移动检测器(BMD)
- 动态编程假设共同的子序列以相同顺序出现,且无法捕获重复子序列。因此,Tichy使用了块移动
S2: a Small Delta and Small Memory Differencing Algorithm for Reprogramming Resource-constrained IoT Devices(INFOCOM ‘21)
摘要
- 现代IoT应用的固件大小逐渐增大,使得现有差分算法面临RAM的瓶颈
- 提出S2
- 减小内存占用的方法
- 基于拓扑排序的原地重建算法
- 流重建技术
- 减小差分文件大小的方法
- 基于预测的编码
- 减小内存占用的方法
解决的问题和方法
- 有限的RAM:现有方法需要把整个旧文件读入RAM
- 方法:基于拓扑排序的原地重建
- 有限的flash空间:现有方法需要把新文件写入不同空间
- 方法:流重建技术
- 进一步减小差分文件大小
- 方法:基于预测的编码
方法
S2DIFF
- 拓扑排序:同Burn的算法
- 基于预测的编码:
- 原始的指令地址参数都用8个字节编码,以支持大文件
- 文章观察到ADD序列的参数t是单调增加的,COPY的参数在拓扑排序前也是单调增加的
- 因此,文章用预测模型对地址参数进行编码:给定一个要编码的COPY的t地址,文章用前几个t来预测它的值,然后用预测的误差对t进行2个字节的编码
- 采用移动平均(MA)模型,因为它能在资源有限的设备上进行有效传输和执行,并且有令人满意的准确度
- 用xz进行二次压缩
S2PATCH
- 流重建
- 逐指令解压,用预测算法恢复指令的地址参数,然后执行
实验
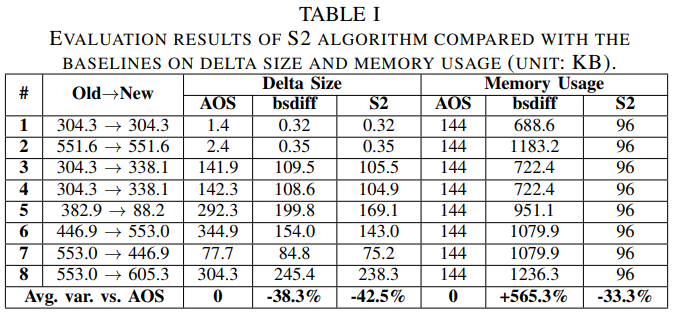
baseline:
AOS:AliOS Things操作系统中默认的增量重编程算法
- 将新旧文件分割成64KB的片段,然后对每个片段执行bsdiff
bsdiff:包含Burn的原地重建算法